If your AI strategy still lives in a "prompt library," you're optimizing for a problem the rest of the market has already moved past.
Back in 2022, prompt engineering was the skill everyone wanted. Job postings demanded it. Consultants sold workshops on it. And for a while, it earned the hype — getting good output from a language model really did come down to how cleverly you phrased the question.
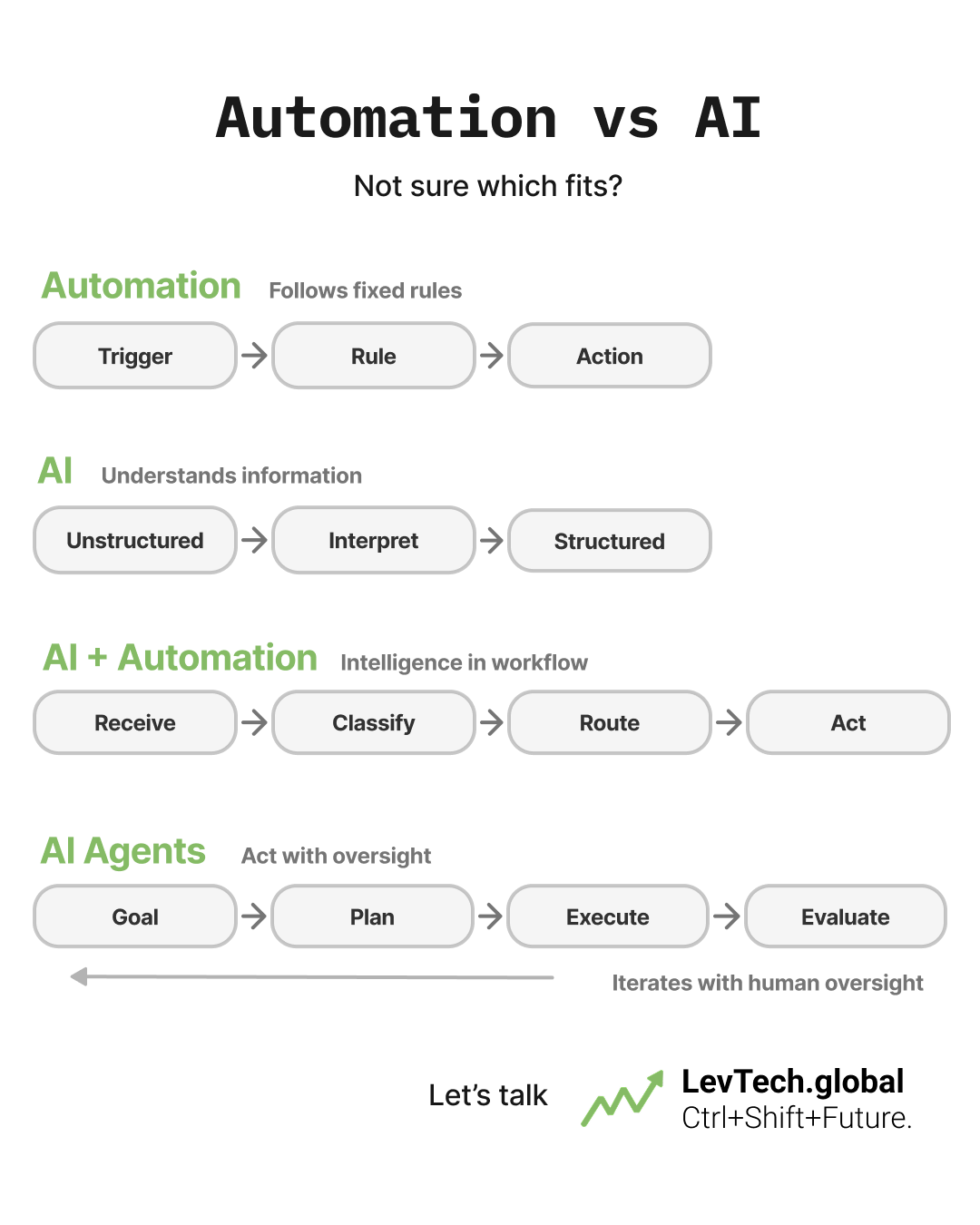
That moment has passed. Not because prompting stopped mattering, but because it stopped being the bottleneck. As AI moved from single chatbot replies into systems that run for hours, touch real business data, and make multi-step decisions, the competitive edge moved with it — first to what the AI knows, then to how reliably it acts, and now to whether it can get better on its own.
Here's the real path that took us from "type a clever prompt" to where enterprise AI actually stands today — and what each shift means for a digital transformation roadmap.
Early AI interactions were one message in, one response out — so naturally, the craft was in the wording. Few-shot examples, "think step by step" instructions, role-play framing: all genuinely useful techniques, and for a couple of years, genuinely differentiating.
But prompting treats every interaction as a one-off. You can hand-craft the perfect instruction and still get a useless answer if the AI doesn't have the right information to work with. That ceiling is exactly why the conversation moved on.
Once AI started getting wired into real products — pulling documents, calling tools, remembering past conversations — the bottleneck shifted. It wasn't about the wording anymore. It was about everything else the AI could see when it generated an answer.
This is context engineering: making sure the AI has the right information, at the right moment, structured the right way. It's the discipline behind retrieval-augmented generation, memory systems, and tool integration — and it's also, quietly, the real explanation for a lot of stalled enterprise AI pilots in 2023 and 2024. Teams blamed the model. The actual problem was usually that the AI never had access to the data it needed to do the job properly.
Two things made this practical at scale:
If there's one investment digital transformation leaders made correctly in 2025, it was here: the data and integration layer, not the chatbot UI on top of it.
Good context still isn't enough once AI starts working autonomously — writing code across dozens of files, running for hours, retrying failed steps without anyone watching every move. That demands a different discipline entirely: coordinating AI that is powerful but unpredictable, without losing your quality bar.
This is agentic engineering — and it's quickly becoming one of the more useful frames for what "AI strategy" actually means in 2026. In practice, it covers:
This shift is backed by real adoption, not just enthusiasm — a growing number of organizations now have AI agents running in actual production rather than just pilots, and budgets are shifting accordingly. But the picture is more mixed than the hype suggests: most organizations are still earlier in this journey than headlines imply, and genuinely production-scale, multi-agent systems are still the exception rather than the norm.
But here's the gap that should worry every digital transformation team: most organizations find it far easier to observe what their AI agents are doing than to verify the agents are doing it well. Visibility without verification isn't governance — it's a dashboard. That gap, not a new framework name, is the real open problem in enterprise AI right now.
The most advanced version of "self-correction" doesn't stop at fixing today's mistake — it rewrites the AI's own tools, prompts, or processes so that tomorrow's version starts smarter than today's. Some research systems already do this with no human in the loop, evolving code and workflows across many generations using automated evaluation instead of manual review.
This isn't purely academic anymore. Some large organizations now run experiment-and-iterate cycles autonomously — testing, debugging, and refining without a person initiating every step — with reported gains that meaningfully beat human-paced iteration.
It's also the stage that demands the most caution. Self-improving systems can optimize exactly the metric you gave them while drifting from what you actually wanted — and if their memory gets shaped by bad or manipulated inputs over time, that compounds quietly. For any organization considering this, governance and evaluation aren't optional add-ons; they're the actual product.
Bring these together and the practical roadmap looks like this:
Is prompt engineering dead?
Not dead — but no longer a differentiator. It's become a baseline skill, similar to knowing how to use a search engine well. The real competitive advantage has moved to context and orchestration.
What's the difference between context engineering and prompt engineering?
Prompt engineering is about the wording of an instruction. Context engineering is about everything else the AI has access to when it responds — documents, memory, tools, and history. One is the sentence; the other is the environment the sentence executes inside.
What is agentic AI, in plain terms?
AI systems that don't just answer a question once, but break a task into steps, take actions, check their own results, and coordinate with other AI agents to get a multi-step job done with minimal human micromanagement.
Are self-improving AI systems safe to deploy in an enterprise?
They can be, but only with strong evaluation and governance in place. Without it, a self-improving system can optimize for the wrong thing or compound small errors over time without anyone noticing until the damage is visible.